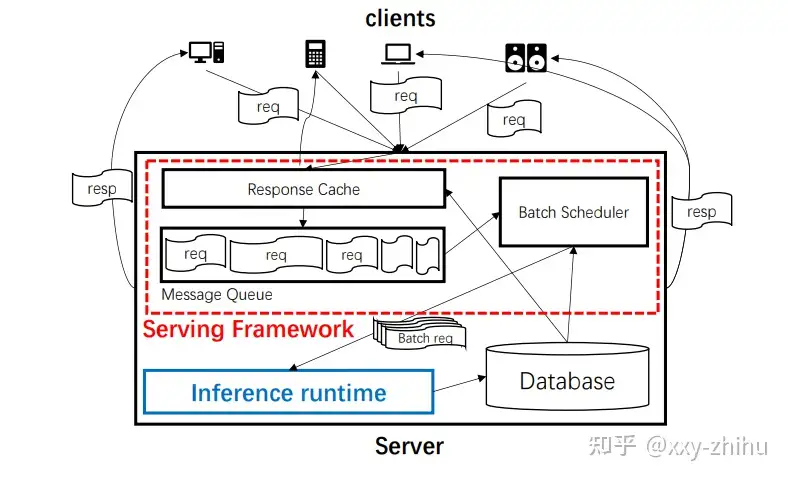
TurboTransformer 解决的主要是变长input的推理优化,目标是减少GPU的footprint、提高吞吐、减少latency。考虑Serving场景,在latency允许的情况下,减少footprint和提高吞吐是最主要的目标,这样可以提高集群GPU资源的利用率。
实现的结构主要包括两块,inference runtime和serving framework。包括三个主要创新的特性,batch reduction(这里不关注)、单次batch内的sequence-length-aware memory allocatioin algorithm、多batch间的DP batch scheduler。sequence-length-aware memory allocatioin algorithm在inference runtime内部,起到内存分配优化的作用。DP batch scheduler属于serving framework的功能,请求可以直接从Cache拿到缓存结果,达到一层优化,没有命中cache的,还可以进入message queue + DP batch scheduler,做batching优化。
支持变长输入的单次batch内的sequence-length-aware memory allocatioin algorithm,更好的平衡memory footprint和分配速度。一般来讲,为了memory footprint少,应该动态申请和释放显存,减少对显存的把持,但是申请、释放速度慢;为了提高速度,应该把申请的显存把持住,减少申请,这样消耗的显存又大。该工作结合了memory cache和时分复用。把显存分成2MB的chunk,通过复用cache的chunk,减少了临时申请;另外通过计算图 + 输入长度,计算出了tensor的生命周期在计算时间维度的offset,在时间上没有overlap的tensor就可以复用显存。
可以想象一下,一个内存的chunk除了size维度,还有时间维度,宽为size,高为时间,构成了一个chunk的时空图。内存分配算法就是在这个chunk时空图上排布tensor(也有时空属性)。包括两种大类情况,一种是在现有的时空图中排布tensor,另外是创建新的chunk时空图。
创建新chunk时空图算法比较简单,就是tensor在时间确定的情况下,没有空间了,就创建一个新chunk,chunk大小是max(2MB, 1.2 * size_of(tensor))。
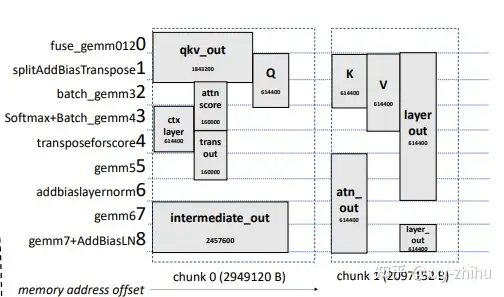
tensor在chunk时空图中的时空排布,空间就是size,时间这里简化为tensor 生产者、消费者op的拓扑序index。n个tensor在chunk时空图上排布,这个问题等价于2D strip packing problem的特例,这个问题是NP hard的,这里按tensor的size贪心地根据非递增序去查找其可以安排进去的chunk时空图(时间复杂度n^2)。查找的方式是遍历chunk时空图中已经排布进去且和该tensor时间上有overlap的tensor,这些tensor中间的空间gap最小的位置,就是插入位置;如果没有找到,找到剩余空间最小但可以放下的;如果还没找到,就新分配chunk。下图是一个例子,纵轴代表时间维度(拓扑序index),横轴代表空间维度,attn score这个tensor就是在ctx layer和Q之间找到了一个最小的gap。可以看到,就是一个找最小符合gap的算法,把内存复用问题,转换成了一个填空问题,在一个给定的时间值,尽量充分的填满空间上的空余gap,从而既使用了分配好的chunk(速度快),又减少浪费(把空间的空隙填满)。
考虑变长输入的DP batch scheduler,多个batch的请求合并后一起处理,提高GPU设备的利用率。在Message Queue中的一定时间段的的请求,可以做batching,这里提出了一个基于DP的sequence-length-aware的batching算法(时间复杂度n^2),把多个请求分成多个batch,达到提高吞吐的目的。DP建模的公式如下,一个时间段的请求,会先按递增序排列(length相近的在一个batch的padding最少),放在request_list中,cached_cost[m][n]表示一个预先试跑的m长n个sequence的平均经验时间开销,states[i]表示0~i的最优分batch的时间代价,它等于最小时间代价的在在j点的分割(0~j用states[j-1]表示,j~i为一个batch,一个batch内用按最长的sequence size,这里是最后一个,来作padding),以此从0到i递增求解DP问题,得到最优的分割。下图有一个分割的例子。
states[i] = min(states[j-1] + cached_cost[request_list[i].len][i-j+1]*(i-j+1) ), 0 ≤ j ≤ i
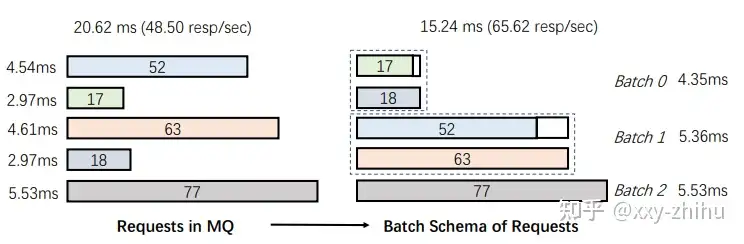
以上,总结了一下TurboTransformers在变长请求情况下,一个请求的显存优化和多个请求的batching优化。优化结果,相比pytorch,memory footprint缩减为1/4到1/6,吞吐提高2~3倍。