原文链接:https://developer.nvidia.com/blog/scaling-language-model-training-to-a-trillion-parameters-using-megatron/
By Deepak Narayanan, Mohammad Shoeybi, Jared Casper, Patrick LeGresley, Mostofa Patwary, Vijay Korthikanti, Dmitri Vainbrand and Bryan Catanzaro
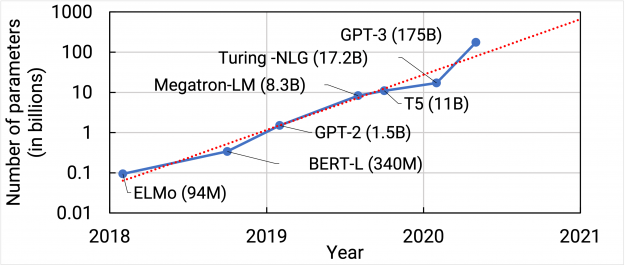
Natural Language Processing (NLP) has seen rapid progress in recent years as computation at scale has become more available and datasets have become larger. At the same time, recent work has shown large language models to be effective few-shot learners, with high accuracy on many NLP datasets without additional finetuning. As a result, state-of-the-art NLP models have grown at an exponential rate (Figure 1). Training such models, however, is challenging for two reasons:
Figure 1. Trend of state-of-the-art NLP model sizes with time.
In our previous post on Megatron, we showed how tensor (intralayer) model parallelism can be used to overcome these limitations. Although this approach works well for models of sizes up to 20 billion parameters on DGX A100 servers (with eight A100 GPUs), it breaks down for larger models. Larger models need to be split across multiple DGX A100 servers, which leads to two problems:
Figure 2. Model parallelism for model with two transformer layers. Transformer layers are partitioned over pipeline stages (pipeline parallelism); each transformer layer is also split over 2 GPUs using tensor model parallelism.
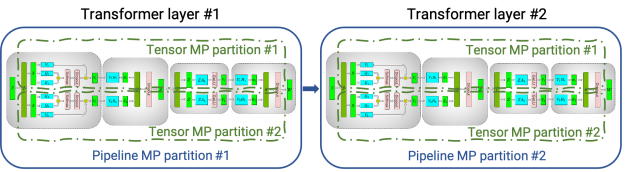
To overcome these limitations, we combined tensor model parallelism with pipeline (interlayer) (model) parallelism. Pipeline parallelism was initially used in PipeDream and GPipe, and is now also available in systems such as DeepSpeed. We used tensor model parallelism inside a DGX A100 server and pipeline parallelism across DGX A100 servers. Figure 2 shows this combination of tensor and pipeline model parallelism. By combining these two forms of model parallelism with data parallelism, we can scale up to models with a trillion parameters on the NVIDIA Selene supercomputer (Figure 3). Models in this post are not trained to convergence. We only performed a few hundred iterations to measure time per iteration.
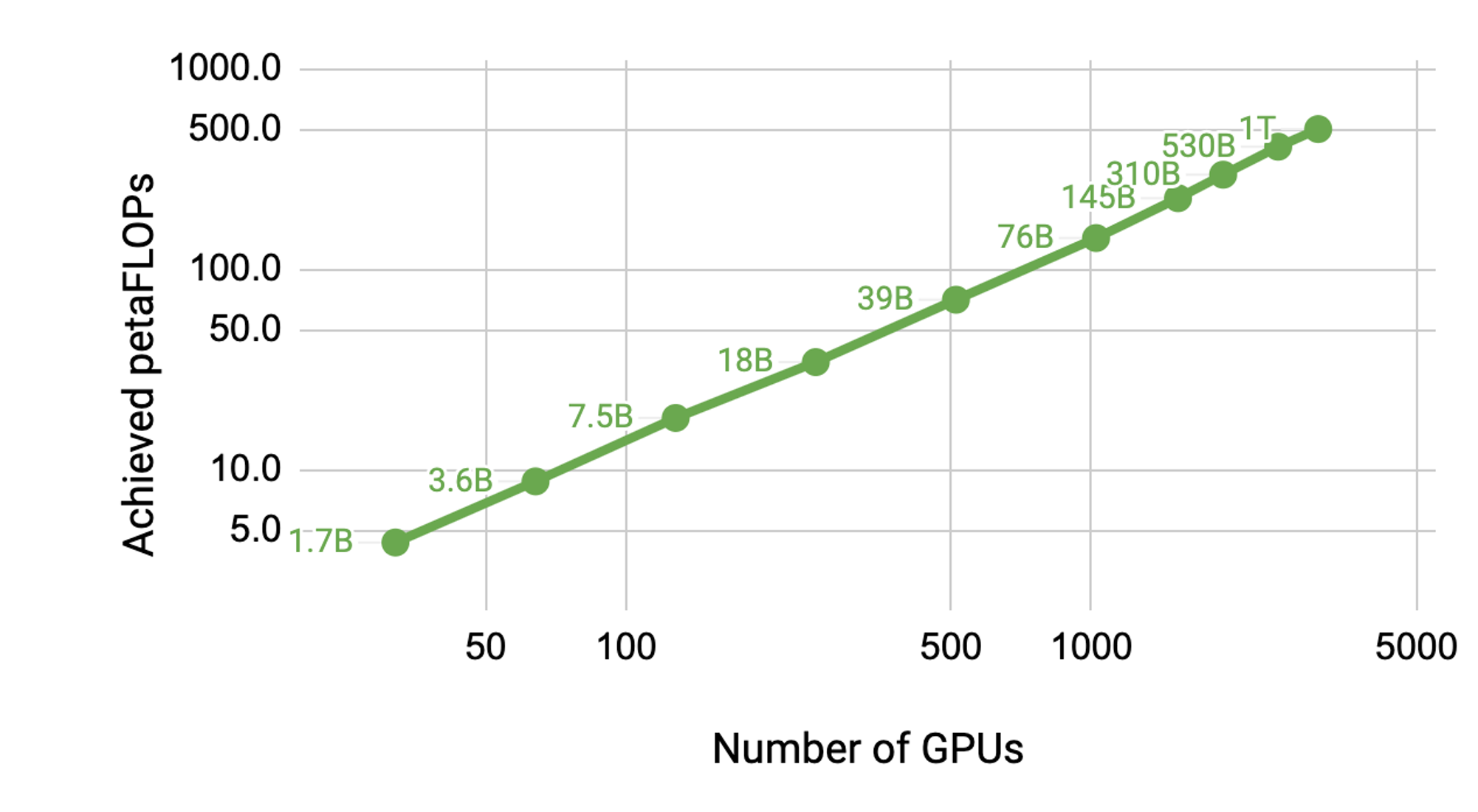
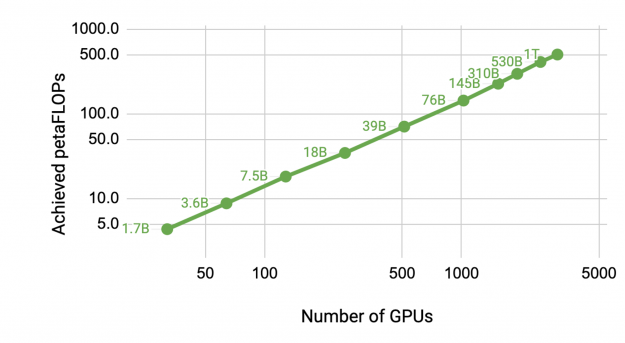
We saw an aggregate throughput improvement of 114x when moving from a ~1-billion-parameter model on 32 GPUs to a ~1-trillion-parameter model on 3072 A100 GPUs. Using 8-way tensor parallelism and 8-way pipeline parallelism on 1024 A100 GPUs, the GPT-3 model with 175 billion parameters can be trained in just over a month. On a GPT model with a trillion parameters, we achieved an end-to-end per GPU throughput of 163 teraFLOPs (including communication), which is 52% of peak device throughput (312 teraFLOPs), and an aggregate throughput of 502 petaFLOPs on 3072 A100 GPUs.
Figure 3. Achieved total petaFLOPs as a function of number of GPUs and model size. For model configuration details, see the “End-to-End Performance” section in this post.
Our implementation is open source on the NVIDIA/Megatron-LM GitHub repository, and we encourage you to check it out! In this post, we describe the techniques that allowed us to achieve these results. For more information, see our paper, Efficient Large-Scale Language Model Training on GPU Clusters.